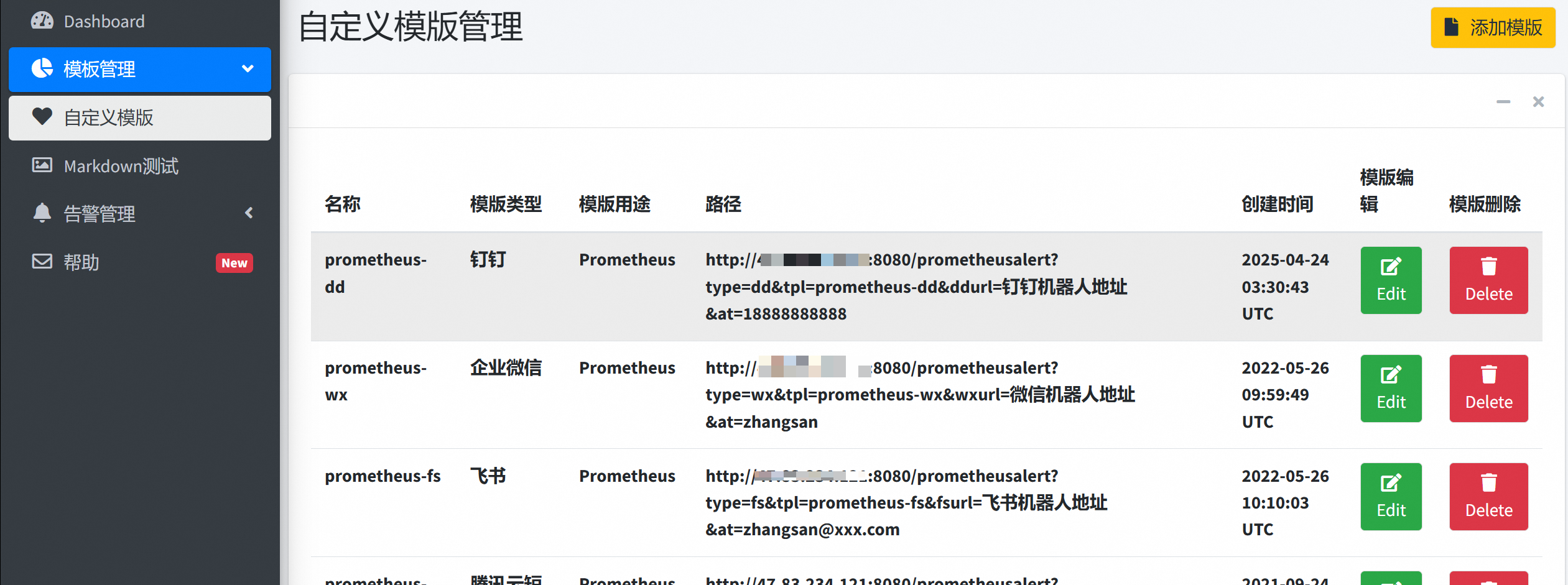
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| global: # 即为全局设置,在Alertmanager配置文件中,只要全局设置配置了的选项,全部为公共设置,可以让其他设置继承,作为默认值,可以子参数中覆盖其设置。
resolve_timeout: 1m # 用于设置处理超时时间,也是生命警报状态为解决的时间,这个时间会直接影响到警报恢复的通知时间,需要自行结合实际生产场景来设置主机的恢复时间,默认是5分钟。
# 整合邮件
smtp_smarthost: 'smtp.qq.com:465' # 邮箱smtp服务器
smtp_from: '1451578387@qq.com' # 发件用的邮箱地址
smtp_auth_username: '1451578387@qq.com' # 发件人账号
smtp_auth_password: 'dkuuifhdskaduasdsb' # 发件人邮箱密码
smtp_require_tls: false # 不进行tls验证
route: # 路由分组
group_by: ['alertname'] # 报警分组
group_wait: 10s # 组内等待时间,同一分组内收到第一个告警等待多久开始发送,目标是为了同组消息同时发送,不占用告警信息,默认30s。
group_interval: 10s # 当组内已经发送过一个告警,组内若有新增告警需要等待的时间,默认为5m,这条要确定组内信息是影响同一业务才能设置,若分组不合理,可能导致告警延迟,造成影响。
repeat_interval: 1h # 告警已经发送,且无新增告警,若重复告警需要间隔多久,默认4h,属于重复告警,时间间隔应根据告警的严重程度来设置。
receiver: 'webhook' # 告警的接收者,需要和 receivers[n].name 的值一致。
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
# 当报警信息中标签匹配到team:node时会使用email发送报警,否则使用webhook。
templates:
- '/etc/alertmanager/config/*.tmpl'
# route根路由,该模块用于该根路由下的节点及子路由routes的定义,子树节点如果不对相关配置进行配置,则默认会从父路由树继承该配置选项。每一条告警都要进入route,即要求配置选项group_by的值能够匹配到每一条告警的至少一个labelkey(即通过POST请求向altermanager服务接口所发送告警的labels项所携带的<labelname>),告警进入到route后,将会根据子路由routes节点中的配置项match_re或者match来确定能进入该子路由节点的告警(由在match_re或者match下配置的labelkey:labelvalue是否为告警labels的子集决定,是的话则会进入该子路由节点,否则不能接收进入该子路由节点)。
route:
# 例如所有labelkey:labelvalue含cluster=A及altertname=LatencyHigh的labelkey的告警都会被归入单一组中
group_by: ['job', 'altername', 'cluster', 'service','severity']
# 若一组新的告警产生,则会等group_wait后再发送通知,该功能主要用于当告警在很短时间内接连产生时,在group_wait内合并为单一的告警后再发送
group_wait: 30s
# 再次告警时间间隔
group_interval: 5m
# 如果一条告警通知已成功发送,且在间隔repeat_interval后,该告警仍然未被设置为resolved,则会再次发送该告警通知
repeat_interval: 12h
# 默认告警通知接收者,凡未被匹配进入各子路由节点的告警均被发送到此接收者
receiver: 'wechat'
# 上述route的配置会被传递给子路由节点,子路由节点进行重新配置才会被覆盖
# 子路由树
routes:
# 该配置选项使用正则表达式来匹配告警的labels,以确定能否进入该子路由树
# match_re和match均用于匹配labelkey为service,labelvalue分别为指定值的告警,被匹配到的告警会将通知发送到对应的receiver
- match_re:
service: ^(foo1|foo2|baz)$
receiver: 'wechat'
# 在带有service标签的告警同时有severity标签时,他可以有自己的子路由,同时具有severity != critical的告警则被发送给接收者team-ops-mails,对severity == critical的告警则被发送到对应的接收者即team-ops-pager
routes:
- match:
severity: critical
receiver: 'wechat'
# 比如关于数据库服务的告警,如果子路由没有匹配到相应的owner标签,则都默认由team-DB-pager接收
- match:
service: database
receiver: 'wechat'
# 我们也可以先根据标签service:database将数据库服务告警过滤出来,然后进一步将所有同时带labelkey为database
- match:
severity: critical
receiver: 'wechat'
# 抑制规则,当出现critical(关键的)告警时忽略warning。
# 下面的这段配置是指如果出现标签为severity=critical的告警,则抑制severity=warning的告警
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# 如果警报名称相同,则应用抑制。
# alertname、cluster和service对应的标签值需要相等
equal: ['alertname', 'cluster', 'service']
# 收件人配置
receivers:
- name: 'team-ops-mails'
email_configs:
- to: 'dukuan@xxx.com'
- name: 'team-X-pager'
email_configs:
- to: 'team-X+alerts-critical@example.org'
pagerduty_configs:
- service_key: <team-X-key>
- name: 'team-Y-mails'
email_configs:
- to: 'team-Y+alerts@example.org'
- name: 'webhook'
webhook_configs:
- url: http://127.0.0.1:8060/dingtalk/webhook1/send
send_resolved: true
|